Quality-driven union table search [M.Sc.]

Context and Problem:
Recently, many large data lakes, such as web tables and Git tables [7], have emerged based on publicly available datasets. To extract knowledge from these corpora of tables, many discovery tasks require efficient and effective algorithms. An example of a table discovery task is union table search [5]. The goal of the union search is to discover table-rows that can be added to a given input table. This can be useful to augment the training data by increasing the number of data points. To achieve this, recent papers introduce various similarity measures. Examples of such measures are the value overlap similarity and semantic similarity [1, 2].
Current similarity measures do not consider the existence of quality constraints in the input table. The discovered tables and their rows could violate the quality rules that exist in the original dataset. Note that, in this thesis, we formulate the quality rules in the form of denial constraints [6].
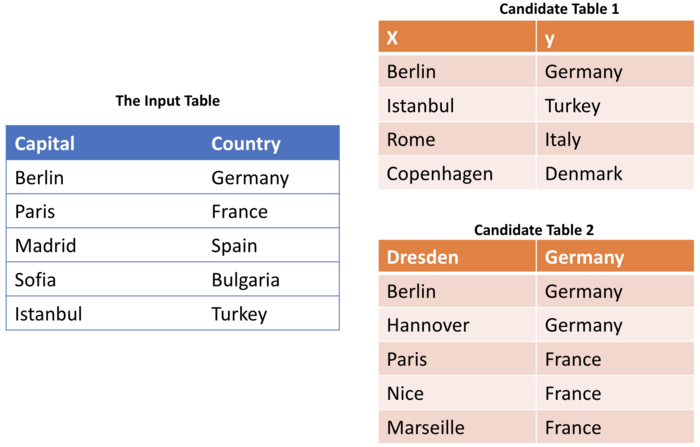
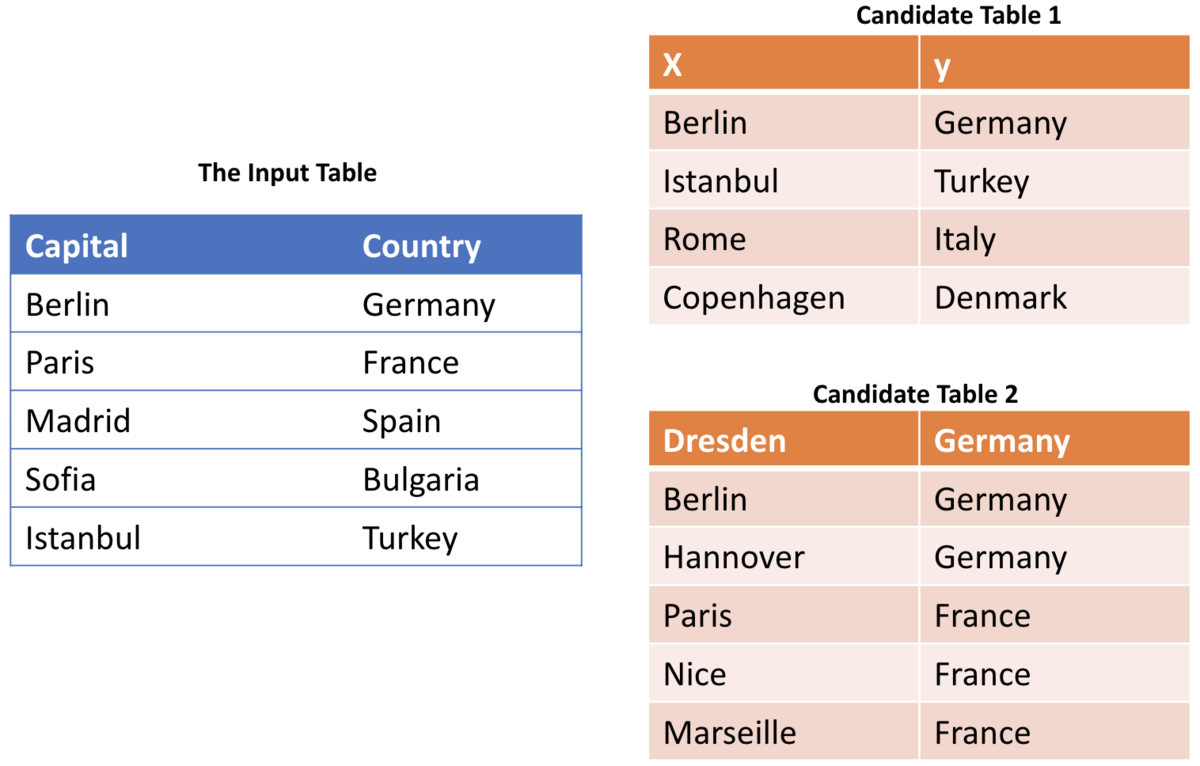
For example, a user-provided table can contain information on country names and their capitals. A simple quality rule that can be defined on this table is a rule that requires a one-to-one relationship between the city and country values. An overlap-based union search approach would initially find tables regardless of this constraint. Therefore, it might find tables that contain country names and city names with an entirely different relationship. The figure depicts this example. The input table contains the capital information of the countries. Candidate table 1, also, contains similar information that can be safely added to the original data without violating the capital → country rule. However, candidate table 2 should not be merged with the input because this candidate table has different semantics than the original table although it has the same value overlap with the input table as candidate table 1. To compensate for this discrepancy, one would need to apply a constraint verification step after the union phase. One can use the traditional data cleaning tools [3, 4] to remove the data points that violate initially set constraints. This approach has two disadvantages:
- The data cleaning approaches are computationally expensive. Increasing the number of rows in the dataset leads to a no-linear increase in the cleaning time [6].
- The data cleaning approaches clean the data in a cell- or row-level granularity. Considering our example, if a unionable table contains random city names instead of capital names, it is rational to ignore the whole table in the first place.
In this thesis, we are looking for an efficient solution that finds the maximum set of unionable tables that do not violate any of the given quality constraints. The student is supposed to read literature on the state-of-the-art union discovery approaches [1, 2] and be able to implement them (or adapt and run the available source codes) as baselines. The student will introduce a new index, algorithm, or pruning strategy that discovers the violating tables before the union operation. In the end, the student should evaluate the approach with regard to time efficiency in obtaining clean table unions.
Prerequisites:
- Strong fundamentals in database concepts.
- Strong algorithm background and familiarity with solving np-hard problems.
- Programming experience in Python, Scala, or Java.
- Interest in data integration and courage to work with large data.
Related Work:
[1] Nargesian, Fatemeh, et al. "Table union search on open data." Proceedings of the VLDB Endowment 11.7 (2018): 813-825.
[2] Bogatu, Alex, et al. "Dataset discovery in data lakes." 2020 IEEE 36th International Conference on Data Engineering (ICDE). IEEE, 2020.
[3] Rekatsinas, Theodoros, et al. "Holoclean: Holistic data repairs with probabilistic inference." arXiv preprint arXiv:1702.00820 (2017).
[4] Mahdavi, Mohammad, and Ziawasch Abedjan. "Baran: Effective error correction via a unified context representation and transfer learning." Proceedings of the VLDB Endowment 13.12 (2020): 1948-1961.
[5] Koutras, Christos, et al. "Valentine: Evaluating Matching Techniques for Dataset Discovery." 2021 IEEE 37th International Conference on Data Engineering (ICDE). IEEE, 2021.
[6] Pena, Eduardo HM, et al. "Efficient Detection of Data Dependency Violations." Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020.
[7] Hulsebos, Madelon, Çağatay Demiralp, and Paul Groth. "GitTables: A Large-Scale Corpus of Relational Tables." arXiv preprint arXiv:2106.07258 (2021).
Advisor and Contact:
Mahdi Esmailoghli <esmailoghli@dbs.uni-hannover.de> (LUH)
Prof. Dr. Ziawasch Abedjan <abedjan@dbs.uni-hannover.de> (LUH)





