Database Joins for Machine Learning [MSc]
Context:
In recent years, data discovery for machine learning (ML) with the goal for data enrichment, has been extensively studied. Data enrichment is the process of enhancing a dataset with informative features or data points. The discovered data is integrated with the training data to increase the accuracy of the ML model. In this thesis we focus on the discovery of and enrichment with informative features.
The availability of large public and enterprise databases facilitates the data enrichment process. Government data [5] and web tables [6] are examples of such openly available data lakes.
Related Works:
Join discovery approaches [1, 2] find tables that can be joined to a given input table.
However, the discovered joinable tables do not necessarily benefit the downstream ML task. Data enrichment methods [3] solve this problem.
COCOA [4] is a data enrichment approach that finds joinable tables that contain highly correlated columns to a target column in the input table. These correlating features can lead to higher ML accuracy.
Problem / Task:
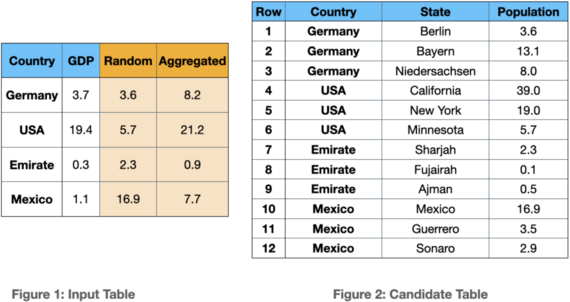
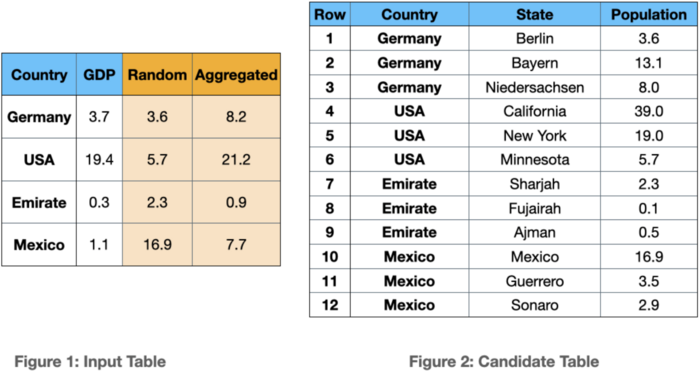
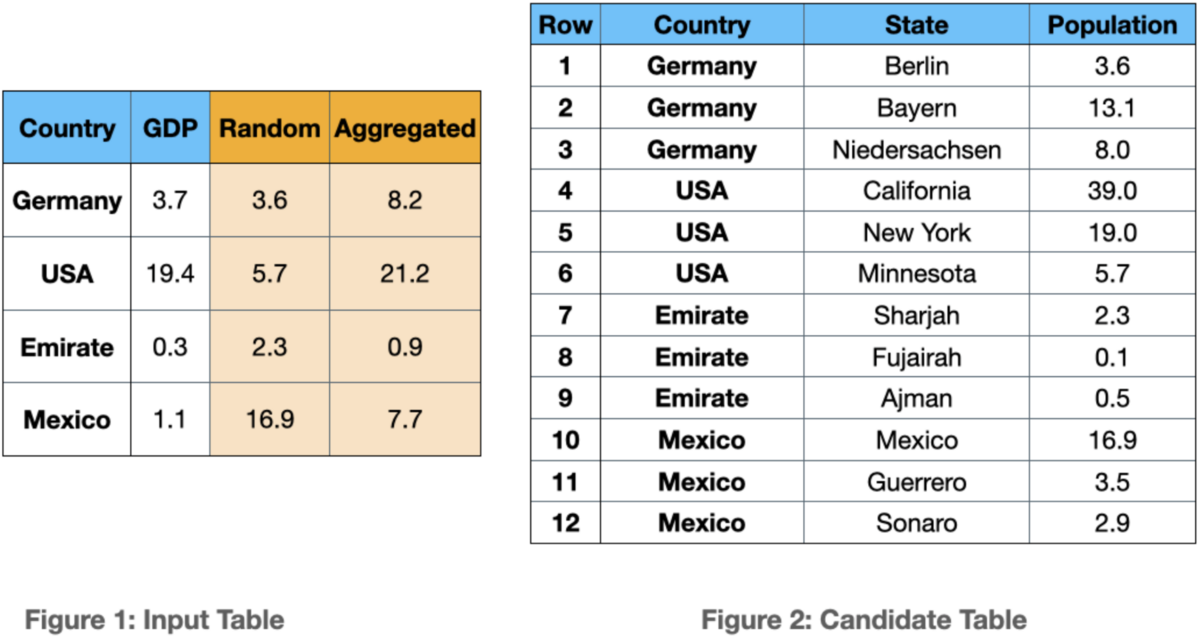
The data enrichment approaches, including COCOA, leverage a two-phase data discovery: Join discovery and correlation calculation. The problem occurs when the join keys include duplicate values. Consider Figure 1 and Figure 2, where they depict an input table and a candidate joinable table respectively. In both tables, the “Country” column is the join key. The GDP column in the input table is the ML target column. As it is shown in the example, the join key in Figure 2 contains duplicate values.
Current join discovery approaches ignore these duplicates. However, the duplicates can provide additional information benefitting the ML model.
Assume that a naive approach selects one row randomly per join key. For instance, rows 1, 6, 7, and 10 are randomly selected to join with the input table. The join results are stored in the “Random” column. After the joining between the selected rows, the correlation calculation is carried out. In this approach, the calculated correlation between the “GDP” and “Population” columns is -0.175.
However, if one aggregates the population values per country name by taking the average (See column “Aggregated”), the ultimate correlation would be +0.95.
The randomly chosen joinable rows lead to the decision that the population does not contain beneficial information for the model as the correlation is close to zero. However, the aggregation of the joinable rows discovers a highly relevant feature.
In this thesis, we would like to understand how duplicate join keys impact the final data enrichment process. In particular, how they change the calculated correlation coefficient. Additionally, we would like to study the effect of different joining approaches, such as aggregating the rows, on the final ML model accuracy.
Prerequisites:
- Programming experience in Python or Java
- Deep understanding of the databases and data structures
- Basic knowledge and Interest in machine learning
References:
[1] Erkang Zhu, Dong Deng, Fatemeh Nargesian, and Renée J. Miller. JOSIE: Overlap Set Similarity Search for Finding Joinable Tables in Data Lakes. SIGMOD 2019.
[2] Mahdi Esmailoghli, Jorge-Arnulfo Quiané-Ruiz, and Ziawasch Abed- jan. MATE: Multi-Attribute Table Extraction. Proc. VLDB Endow. 15, 8 (2022).
[3] Aécio S. R. Santos, Aline Bessa, Christopher Musco, and Juliana Freire. A Sketch-based Index for Correlated Dataset Search. ICDE 2022.
[4] Mahdi Esmailoghli, Jorge-Arnulfo Quiané-Ruiz, and Ziawasch Abedjan. 2021. COCOA: COrrelation COefficient-Aware Data Augmentation. EDBT 2021.
[5] www.Data.gov
[6] wwwdb.inf.tu-dresden.de/misc/dwtc/
For a detailed introduction to the topic, please get in contact via email.
Advisor and Contact:
Mahdi Esmailoghli <esmailoghli@dbs.uni-hannover.de>
Prof. Dr. Ziawasch Abedjan <abedjan@dbs.uni-hannover.de>





